
1:什么是个性化推荐?
随着互联网的飞速发展,电子商务网站规模的扩大,如何在海量的数据中挖掘出有用的信息成为各大互联网公司亟需解决的问题。
个性化推荐系统(Personalization recommendation system)就是解决这么一个问题。简言之,它是利用互联网收集用户的行为记录,并在此基础上分析用户偏好,然后向用户推荐一些个性化的商品或服务。
举个栗子,张三是一个IT工科男,最近想深入学习C++,刚巧其师兄推荐他一本《C++ Primer Plus》,于是张三打开了亚马逊的网站,在搜索框中输入:C++ Primer Plus。回车,选了第一本C++PrimerPlus买了下来。
第二天张三拿到这本书后,出于某些原因,决定退货。
当他再次点开亚马逊的首页时,发现首页一栏“与您浏览过的商品的相关推荐”,罗列了许多C++学习的经典书籍:C++ Primer、effective C++、esential C++、C++大学教程等等。最后张三退了《C++ Primer Plus》购买了推荐栏的《C++ Primer》开始了“快乐”的C++学习路程……
这里就用到了基于内容(content-based)的个性化推荐算法。
2:个性化推荐系统有哪些算法?
- 基于内容的推荐算法(content-based)
上面例子中提到的算法,是基于内容的的推荐算法,也是亚马逊最早采用的推荐算法,并对其增加营收起到了很大作用。基于内容的推荐系统只需要知道两类信息:物品特征的描述和描述了用户兴趣的行为记录。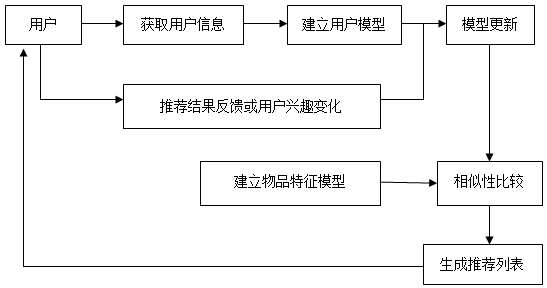
还是上面的栗子,亚马逊的推荐系统首先记录了张三的行为记录(输入C++ Primer Plus关键字、浏览C++相关书籍)构建了张三的用户偏好模型,随后构造《C++ Primer Plus》的物品特征模型,然后经过相似度计算,求出与C++ Primer Plus相似度较高的物品作为推荐列表展现给目标用户。
- 基于协同过滤的推荐算法
在20世纪90年代初期,基于协同过滤的推荐算法就已经被提出,一般来说,学术界将协同过滤分为两种类别:基于记忆的协同过滤(memory-based CF)和基于模型的协同过滤(model-based CF)。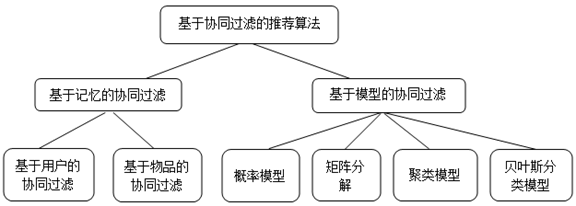
- 基于用户(user-based)的协同过滤算法
主要思想是——利用相似度高的用户向目标用户推荐商品。
举个栗子,张三喜欢在亚马逊上购买IT相关的书籍,算一算他已经买了《C++ Primer》、《effective C++》、《essential C++》……
这个时候呢,有这么一个同学李四,他也喜欢购买IT相关的书籍,他买的书有《C++ Primer》、《effective C++》、《STL源码剖析》。可以看到他们两个购买的书籍有很大的相似性,我们可以暴力的认为张三和李四具有很高的相似度,我们暂且称李四是张三的最近邻。
某一天,张三打开亚马逊想看看有什么书可以买来充电,此时推荐系统会从张三的最近邻李四购买的书单中,向张三推荐李四买了而张三没有买的书籍。显然,此时推荐系统会向张三推荐《STL源码剖析》,张三买回书本后开始了“快乐”地STL学习之旅…… - 基于物品(item-based)的协同过滤算法
主要思想与基于用户的推荐算法类似,利用物品的最近邻向目标用户推荐物品。 - 基于矩阵分解模型(Matrix Factorization Model)的协同过滤算法
在推荐系统中,矩阵分解模型将用户和物品映射到一个共同的隐含因子空间R(该空间中向量的每一个维度代表一个隐含因子)。例如,在电影推荐中,用户的某个隐含因子可能代表用户喜欢动作类电影的程度,另外一个隐含因子可能代表用户的性格类型等;电影的隐含因子可能代表电影的类别(如动作、科幻)、电影适合的人群等。每位用户u被特征化为隐含因子向量Vu∈R,用来代表用户的喜好或兴趣;同理,每个物品i被特征化为隐含因子向量Vi∈R,用来描述物品的关键特征。
- 以及基于概率模型、聚类模型、贝叶斯模型的协同过滤算法,此处不在做详细介绍。感兴趣可自行查看相关文献。