
前面的一篇文章提到个性化推荐领域中的一个重要的算法——协同过滤推荐(Collaborative Filtering recommendation),今天让我们再深入的了解它的一个分支领域吧。对,就是相似度计算。
内容概括:
1.引言
2.相似度计算的方法主要有哪些?
3.经典计算方法——余弦相似度计算
4.实例
1.引言
基于用户的协同过滤推荐,该算法认为一个用户会喜欢喝他有相似兴趣爱好的用户喜欢的产品。因此,要对一个用户做推荐,首先得找到和他兴趣爱好相似的用户。
要说协同过滤是推荐系统的核心,那么,说相似度计算是协同过滤的核心也不为过。
举个栗子吧:
甲同学:特别喜欢吃麻辣烫、喜欢吃关东煮、既不喜欢也不讨厌吃鸭血粉丝、讨厌麻辣香锅、特别讨厌臭豆腐。
乙同学:特别讨厌吃麻辣烫、讨厌吃关东煮、既不喜欢也不讨厌吃鸭血粉丝、喜欢麻辣香锅、特别喜欢臭豆腐。
这个时候班里来了一个新同学女生丙(哦,忘记说了甲乙是男生,丙很漂亮,甲乙已经安奈不住了,于是都展开了对丙美美的追求……)这个小丙呀,原来也是个吃货,咱来看看美丙是什么口味:
丙同学:特别喜欢吃麻辣烫、既不喜欢也不讨厌吃关东煮、讨厌吃鸭血粉丝、喜欢麻辣香锅、特别讨厌臭豆腐。
问题来了 ,这个小丙该接受甲同学呐还是接受乙同学呐?
细心观察会发现,甲乙丙对五种小吃的喜欢程度,应该可以大致判断出来,美丙跟甲的口味相似度要大一些。最终,美丙选择了甲。学渣乙表示不服,还是纠缠不放,这该怎么办呢?
不必纠结,我们吃货有我们吃货的解决办法,甲说让我们用数据说话吧:我们分析一下,有甲乙丙三个同学、五种小吃,以及甲乙丙对五种小吃的喜爱程度。让我们来量化一下这五种喜欢程度(特别喜欢、喜欢、不喜不讨、讨厌、特别讨厌),分别对应五个评分(5,、4、3、2、1),数字越大表示喜欢程度越大,反之亦然。那么我们可以得到如下的表:
等等……博主好像跑偏了没有按着提纲来总结。咳咳,下面我们先总结有哪些相似度计算方法:
2.相似度计算的方法主要有哪些?
不同的相似度计算方法具有不同的公式和优缺点,能适应不同的数据环境。
(1)余弦相似度
余弦相似度是一种典型的Correlation相似度方法。它将用户的历史评分看作是n维向量,即使用i、j分别表示用户i和用户j的历史评分信息。其中向量的第k个元素是该用户对第k个产品的评分值,未评分产品用0代替。用户i和用户j的余弦相似度可以用两个向量的夹角余弦表示,即:
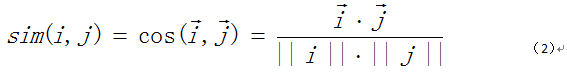
(2)修正的余弦相似性
余弦相似性度量方法中没有考虑不同用户的评分尺度问题,修正的余弦相似度量方法通过减去用户对项目的平均评分来改善上述缺陷,设经用户i和用户j共同评分的项目集合用Iij表示,Ii和Ij分别表示经用户i和用户j评分的项目集合,则用户i和用户j之间的相似性为:
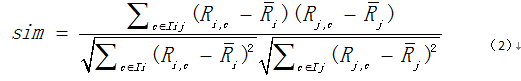 其中,Ri,c表示用户i对项目c的评分,Ri拔和Rj拔分别表示用户i和用户j对项目的平均评分。
其中,Ri,c表示用户i对项目c的评分,Ri拔和Rj拔分别表示用户i和用户j对项目的平均评分。
(3)皮尔逊相关性(Pearson Correlaton,PC)
皮尔逊相关性亦是一种典型的Correlation相似度方法。它是自然科学领域中广泛用于度量两个变量间线性相关的方法之一。在UserCF(基于用户的协同过滤算法)中,它可以有效描述两个用户在若干个产品上评分变化趋势的一致程度。其计算公式: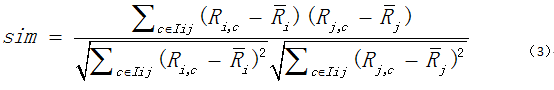
其中,Ri,c表示用户i对项目c的评分,Ri拔和Rj拔分别表示用户i和用户j对项目的平均评分。
3.经典计算方法讲解——余弦相似度计算
下面简单的介绍一下余弦相似度的计算方法,比如有A、C两个五维向量:A(5,4,3,2,1)、C(5,3,2,4,1),那么AC相似度为
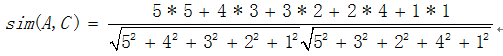
惊叹高中的三角函数还有这样简单暴力实际的应用场景。啊啊啊~
4.实例
接着1中的甲乙追求美丙的故事说下去,话说上一回,美丙最终选择了学霸吃货甲后,乙表示不服。遂,甲拿出了下面的数据:
甲乙丙对五种小吃喜爱程度量化后的数据如下:
 分别计算甲丙,乙丙相似度:
分别计算甲丙,乙丙相似度:
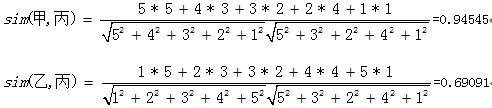
由上面结果可知,甲丙的相似度大于乙丙的相似度。甲同学将数据甩在乙面前,搂着美丙转身走在夕阳的黄昏下,赶去共享区大吃了一顿六块钱的麻辣烫……
故事还没完,这个时候班里又来了一个女生美丁,其美貌不亚于美丙。来看看丁同学的口味量化后的数据: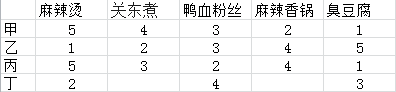
由上表可知,丁同学讨厌麻辣烫,喜欢鸭血粉丝、既不喜欢也不讨厌臭豆腐,这里有个问题,丁同学从来没有吃过关东煮和麻辣香锅。来到了大学后发现居然还还有这两个小吃的存在(我们这里规定未吃过的小吃为0分)那么问题来了,该推荐给丁同学什么呢?
我们还是用数据来说话,如下,算出甲丁、乙丁的相似度: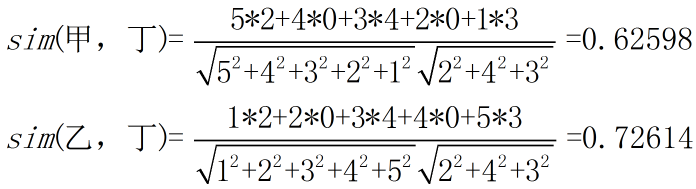
由上面的计算结果可知,乙跟美丁的口味较甲更相似(于是同学乙也走上了人生巅峰),那么,我们要推荐给丁什么小吃呢?有如下步骤:
(1)找出与目标吃货丁的相似度高的吃货(这里是乙),我们暂且称其为目标用户的最近邻。
(2)从最近邻吃过的小吃清单中,找出评分较高并且目标吃货没有吃过的小吃,推荐给目标吃货。
所以,我们从乙吃过的小吃中,找出丁没有吃过的小吃,并且评分最高的小吃推荐给美丁。这里我们推荐给美丁的小吃是——麻辣香锅。
故事的结局是美好的。
讲的浅显易懂
相似度计算这里可以考虑模糊控制里面的贴近度么?